An RSS feed creator can help you generate an RSS feed for your website or other people’s websites. Having your own RSS feed is a great way to deliver content to your audience automated and efficient. Anyone who subscribes to your website can get access to your latest posts. Additionally, you can use RSS creators to access your competitors’ feeds to monitor their performance and the trends they follow.
In this article, we’ll look at some of the best RSS feed creators to help you and your readers stay current.
Inside this Article
- What Is an RSS Feed?
- 12 Best RSS Feed Creators for Your Website or Blog
- What Is an RSS Feed Creator?
- What About an RSS Feed Reader?
- What Is the Difference Between an RSS Feed Creator and an RSS Feed Reader?
- How to Create an RSS Feed for Your Website
- Why Would You Want to Create an RSS Feed for Your Website?
- Final Thoughts on the 12 Best RSS Feed Creators for Your Website or Blog

What Is an RSS Feed?
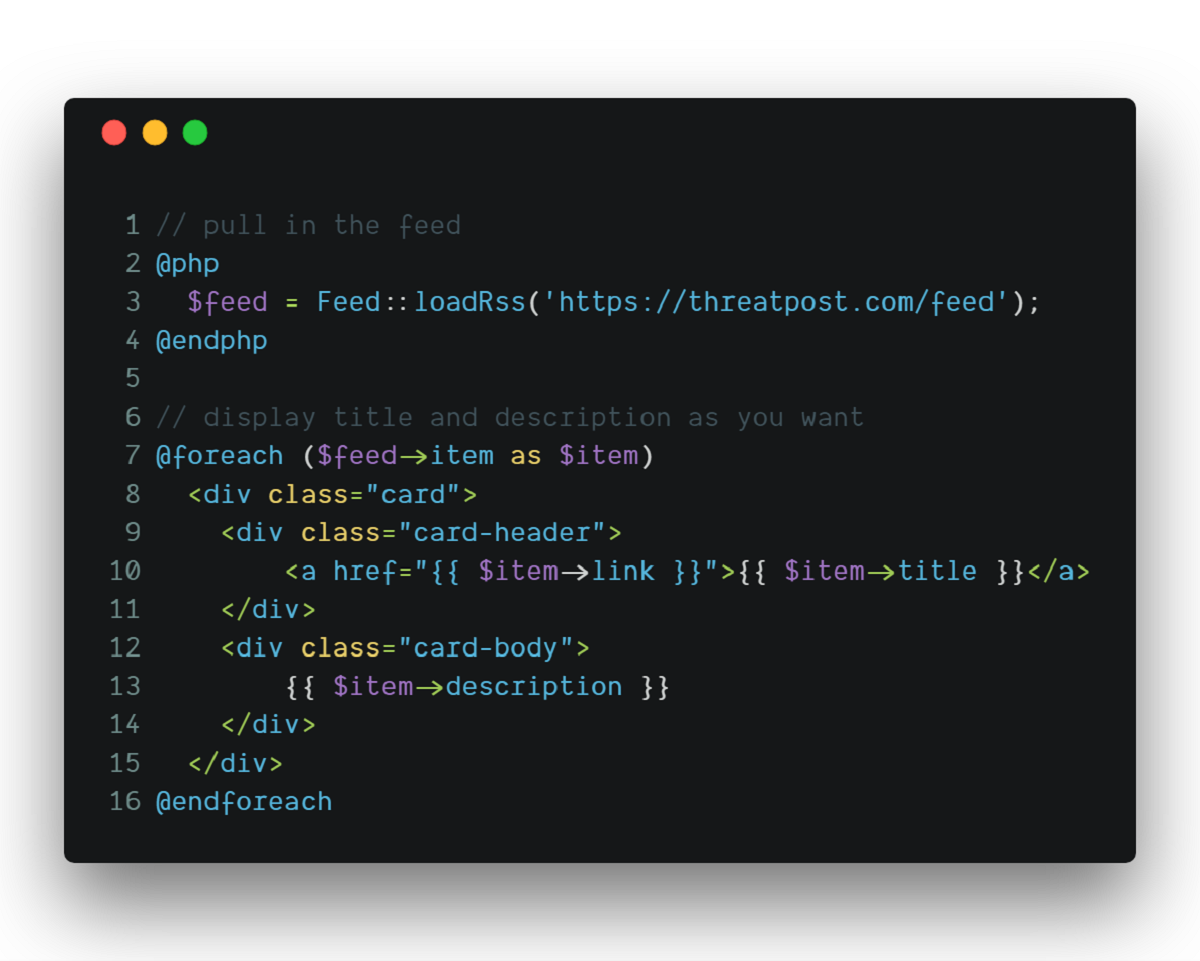
An RSS feed is simply a text file with code that reflects all the changes made to a webpage in real time. The acronym stands for “really simple syndication” or, in other words, straightforward syndication or site summary. The term refers to the system being used to automate the delivery of notifications about the latest content to readers.
An RSS file is typically stored in XML (Extensible Markup Language) format. The XML variant of the file usually contains both the actual data and coded instructions as to how the data should be transported and stored. The combination of code and text in an XML file means that only special software can read it.
Each entry on the RSS feed represents a single article from a website or blog, including snippets of information called metadata. The metadata consists of the title, date of publication, summary, and publisher of the article. The link (URL) to the original article is also included.
12 Best RSS Feed Creators for Your Website or Blog

Most content management systems like Blogger and WordPress have built-in plug-ins that automate the RSS creation for your website or blog. However, if your content management system doesn’t have RSS built-in, you will have to rely on a third-party program to generate one for your website. Here are some of the best RSS feed creators on the market:
1. WebRSS
WebRSS lets you create an RSS feed for your website. It offers tools to help you market your feed to visitors of your websites to entice them to follow your posts through their feed readers. You can even customize your RSS feed widget using 170 different colors.
Aside from helping you create an RSS feed for your website, WebRSS also allows you to track the RSS feeds of websites related to yours. You can add feeds like weather updates, news, or stocks to the home page of your website. This is a great way to populate your website with helpful information. Additionally, you can convert these feeds into alternative file formats, including HTML, Java, PHP, or AS.
2. Surfing Waves
Surfing Waves is a simple and easy-to-use RSS feed creator. The procedure they impose for creating an RSS feed is relatively simple. You simply need to post your website’s URL or existing feed URL, customize the specifications for the widget, and then copy and paste the resulting HTML code onto your webpage to create a feed. That way, your readers always know your latest articles, and you can even include feeds from other websites if you want to. On top of that, the service is entirely free and accessible online.
3. RSS Feed Generator
RSS Feeds Generator is a free online resource and RSS feed creator. Its primary role is to help you create an RSS feed for your website, so your readers can keep track of your content. This tool is keyword-based, which means you have to add in some keywords to manage your feeds. Editing your feeds to make them easier to read is simple enough, as the system doesn’t require any basic knowledge of XML.
In addition to managing your RSS feed, you can keep track of external feeds and have them posted on your website. If your website has to do with e-commerce, you can have feeds from eBay or Amazon on your home page. You also have the option to have RSS feeds from other websites sent to your email.
4. FeedForAll
FeedForAll is another free and easy-to-use online RSS feed creator. The software offers a quick and easy way to generate an RSS feed for your website and other websites. The software offers up tools to help you maintain your feeds with little effort from day to day. For example, you can automate the schedule for the release of your feeds so that you can go about your business after posting new articles.
The software also offers a way to validate your XML files or convert them into HTML, CS, or text formats. You can also include a podcast (i.e., iTunes compatible podcast) in your feeds if you want. If you have older RSS feeds, you can enhance them with advanced feed properties to make them look more professional.
5. RepeatServer

RepeatServer is another practical and free RSS feed creator and host. It allows you to create an RSS feed for your website to offer your readers a way to receive updates about your posts in real-time. You can create and manage multiple feeds and then have them published to local or network drives. Moreover, you don’t have to limit yourself to using the English language with your posts. You can add posts in other languages such as Japanese, Chinese, Greek, Russian, etc.
RepeatServer also offers external tools that can help you create and manage RSS feeds for publishing over the internet and validating your RSS files to ensure they are in working order.
6. Five Filters
Five Filters is a straightforward yet practical tool for creating and managing RSS feeds. You can customize the metadata for each feed, including the title, description, copyright info, language, and publication date. You also get text editing options that let you adjust font, size, color, and style. Additionally, you can segregate your feeds by topic and have them appear in clusters. Moreover, you can insert links, external images, and tables as a way to supplement your articles.
Five Filters has a free and premium version. The premium access offers more control over your feeds and also reduces the cache time.
7. Feedly
Feedly is another practical yet sophisticated solution to your RSS feed woes. The tool lets you create and manage RSS feeds for websites you want to follow, requiring no programming skills. The software allows you to organize your feeds into collections, and you get to receive updates from multiple websites simultaneously.
The software features a collaborative tool that allows you to share your feed with a group of people. In addition, the software has its own AI research assistant called Leo. Leo automatically reads your articles and organizes them according to the theme. You can also provide the research assistant with keywords you want to see, prioritizing articles with those keywords.
Feedly has a free and premium version. The premium version will allow you to add notes and highlights to your content and get you automated searches and Google Alerts.
8. myRSScreator
myRSScreator is another straightforward solution for your RSS needs. The program helps you create an RSS feed for your channel to help you keep in touch with your subscribers. You can quickly post new content to your feed and edit or delete it with a single click of a button. To keep your content relevant and interesting, you can add images, audio files, and photos to your posts.
A unique feature lets you add a “browser feed” button to your website’s home page. This feature allows readers without access to feed readers to read your content or listen to your podcast via browser extension instead. The software also validates your RSS feeds automatically to make sure that it is in working order. A private links area is provided for when you want to download RSS readers and reports.
9. RSS.app
RSS.app is a simple and free RSS feed creator. It offers a simple process for generating RSS feeds both for your website and other websites that you want to follow. If your website doesn’t have its feed yet, RSS.app can create it for you. You only need to provide the necessary details for your feed, and the software will automatically send notifications to your readers each time your website receives updates.
If you’re more interested in channeling external feeds into your website, you can easily do so with RSS.app. You can generate feeds for websites without visible RSS feeds. You can even sponsor your feed to appear in someone else’s blog or have a sponsored feed appear in yours. That is, you can pay another blog owner to show your feed, or you can have someone else pay you to show theirs.
RSS.app allows the sponsor to take control of their feeds, so you don’t have to. For example, they can select specific keywords to filter the articles that appear on the feed. The tool also allows sponsors to modify metadata or set limits for the number of words to appear per article.
10. Feed43

Feed43 is a free and open-sourced RSS feed creator and manager. The software’s primary purpose is to generate RSS feeds from websites that do not have them. Feed 43’s specific process for extracting feeds leans towards the more technical side of things. However, you can expect the website to offer you some guidance, so you don’t have to figure everything out alone.
Some of the steps include typing in the main URL of the website and sifting through article titles. By allowing you to sift through titles and keywords, the software gives you precise control over your feed. But then again, the highly technical nature of the process up offsetting the benefits of customization.
Feed43 has a free and paid version, but the free version should suffice for basic RSS feed creation. The free version is open for everyone to use, meaning you don’t have to register to use it.
11. Scrapy
Scrapy is another practical and relatively modern RSS feed creator. It lets you create an RSS feed for your website and provides special tools to help you enhance your feed. You also get plenty of design options for your widget to make it easy to spot on your website. It also validates XML files to make sure that the feed is working correctly. The service has both a free and subscription-based version, but the free version should suffice for basic RSS feed creation. Not only that, but you can also integrate the program with content management services like WordPress and Blogger.
12. MySiteMapGenerator
MySiteMapGenerator is a sitemap generator with its RSS feed creator. This program can help you create an RSS feed for your website and other websites that don’t have their own. The software collects feeds from up to ten websites at a time to stream into your website. The fees appear in alternating fashion, so your readers can get multiple updates at a time. You also get to choose specific keywords that the program will use to filter your feed. In addition, you can also select the metadata that appears for each feed. Luckily, both the generator and RSS feed creator are accessible for free.
What Is an RSS Feed Creator?

An RSS Feed creator is a special program that generates an RSS feed for your website or other websites. A feed creator helps you create an online channel or feed that automatically reflects new uploads to your website or blog. The software allows you to select the articles or topics you want to highlight on your website, and it offers tools to help you customize your feed’s presentation.
An RSS feed creator helps create feeds either from your website or external websites. That is, you can either present your own website’s latest articles or get external feeds into your website.
There are two possible reasons why you may want to channel feeds from other websites into yours. The first is that it serves as a way for you to keep your website relevant and informative, which helps to increase website traffic. The second reason is that it is an excellent way to keep a close eye on your competitors, check for trends and site performance.
What About an RSS Feed Reader?

An RSS reader is special software that collects RSS feeds from multiple websites. Think of the RSS reader as the inbox for recent articles from your favorite websites. When you subscribe to the RSS feed, the RSS reader will automatically check that website for updates at regular intervals. The software will then download the content straight from the website and into your reader.
A single RSS reader can collect content from hundreds of websites (including blogs, podcasts, company websites, etc.). This means you won’t have to go through the time-consuming manual search for topics and websites on the internet.
Each item on the feed represents an article. It will include a title, summary, publishing date, author, and the URL link to the original article. In most cases, clicking on the URL allows you to read the full text of the article straight through the reader.
An RSS reader will allow you to organize the feeds that appear on your page per theme or topic. For example, you can create a folder entitled “Business News.” It will contain all feeds from business websites, naturally. To reduce the visual clutter, you can also separate feeds that you hardly ever read from the feeds you read regularly.
What’s the Difference Between an RSS Feed Creator and an RSS Feed Reader?

We must also establish the distinction between an RSS creator and an RSS reader. Both types of software deal with RSS feeds, and both are necessary for receiving updates from multiple websites. However, the two differ in terms of purpose and the order in which they are used. The former generates feeds for websites that don’t have them, while the latter collects updates from multiple feeds you to read through a single platform.
An RSS reader would not be able to read a webpage without an RSS creator, simply because the webpage must be in the correct format to be read by the reader. Therefore, an RSS creator necessarily precedes an RSS reader in terms of function, although each software has a role in the process.
To clarify the differences between these programs, let’s use the analogy of an e-book. If an RSS feed is an e-book, then the RSS feed creator can convert it into e-book format while the RSS reader allows the e-book to be read.
How to Create an RSS Feed for Your Website

The potential benefits of having an RSS feed at the ready on your website can’t be ignored. However, you should know some technicalities involved with creating a feed, even when you have an RSS feed creator to help you out. This is why it’s so important to at least familiarize yourself with the process before diving in. Here are the steps for creating an RSS feed for your website:
1. Select an RSS Feed Creator
Before you can even get an RSS feed for your website, you must have a website. And to have a website, you need to have both a content management platform and a web hosting provider. Your choice of a web hosting provider is crucial since it determines how long your website can stay up and running on the internet.
Most content management platforms allow you to create RSS feed automatically. But select platforms don’t come with their own RSS tools, so you have no choice but to rely on a third-party RSS feed creator. These programs are specially designed to help you create and manage feeds in one place.
2. Input the Required Information
After you have selected an RSS feed creator, the next thing you need to do is provide the main URL of your website. After that, you’ll have to enter channel information, including its title, description, copyright date, language, and so on. It’s also possible for you to include an image in the XML code. After that, you can edit individual feeds and provide a title, link, and description. Most programs allow you to start with ten to fifteen entries, though most software will enable you to adjust the number based on your needs.
3. Save Your XML File
Once you’ve included all entries you want your readers to see, you need to save them. The program will then ask you to save your file in XML format, and you should agree to the changes. The resulting file should have a different tail (i.e., rss.xml). Now that you’ve created a feed, you need to upload your feed’s XML file to your web server.
4. Upload the XML Feed into your website
Once you have successfully uploaded the file, you should get a URL link that looks something like techcrunch.com/europe/feed. This link will be the permanent link to your RSS feed and will be the same one that your readers will need to export into their respective RSS readers.
Why Would You Want to Create an RSS Feed for Your Website?

An RSS feed is a great way to maintain traffic for your website or blog. When your readers add your website to their RSS reader feed, they can automatically receive notifications about your latest posts through a web browser extension or an RSS feed reader.
Having an RSS feed is a great way to keep in touch with your audience. Because let’s face it, there are far too many websites on the internet, and you have hundreds of websites to compete with all the time. As such, you can hardly expect your readers to keep coming back to your website without any good reason. By automating sending updates to your readers, you are reinforcing the value of your website to your readers. Moreover, the fact that updates are sent to your readers automatically makes it very convenient for them. It’s convenient because they no longer have to go and check for updates for every website manually.
An RSS feed is also a great alternative to sending email notifications to your subscribers. Email has been the staple for online communication for decades now, and the truth is its charm is beginning to fade away. You can trust that most of the encouraging emails that you send to your readers will end up unopened. Even worse, they can end up in the spam bin. By automating the notification process through RSS, you can avoid sending spam emails to your audience while also increasing the chances of your content being read. It also allows you to get in touch with your audience without resorting to annoying tactics.
Final Thoughts on the Best Feed Creators

RSS feed creators have evolved over time, and they have come to have different functions. Some only offer to help you with creating an RSS feed for your own website. Meanwhile, others only help you with generating RSS feeds for websites other than your own. Still, some programs handle both tasks with equal ease, and these types of creators present a two-fold advantage for website owners. That is, website owners can offer their readers a way to access their content automatically. At the same time, they can keep an eye out for trends by looking at the articles and posts of their competitors.
In summary, you have a spread of options to choose from, and you can try multiple options until you find the right one.